Dear community-members!
I am trying to make our business more efficient and really love textblaze! I need to be able to just type an organisation-number for a business and then the result will be that the information is automatically transferred to a template.
The url of the webpage is: Nøkkelopplysninger fra Enhetsregisteret - Brønnøysundregistrene where "XXXXXXXXX" is the organisation-number.
An example-org.nr you can use to test if the corect values is grabbed is:
I need to get the following information from the webpage:
"Daglig leder" (CEO)
"Styreleder" (Chairman of the board)
"Innehaver" (Owner)
This should be inserted in this template:
Admin + faktura kundenavn
Email-ID admin:
Email-ID faktura:
INFO OM BEDRIFT
Org.nummer:
Kundenummer:
Daglig leder:
Styreleder:
Innehaver:
Relevant kontaktinfo:
INFO OM SØKER
Navn:
Epost:
Tlf:
Vipps-navn:
Vipps samsvar med søkers navn:
BankID-verifisering:
Navn:
Fødselsdato:
Samsvar med fødselsår Proff:
Søkt om kredittgrense:
BEGRUNNELSE FOR GODKJENNING/AVSLAG:
NOTATER:
I will be superthankful if anyone of you can come up with the solution to this problem  Wish you all a wonderful day!
Wish you all a wonderful day!
Best regards from Stein in Norway
1 Like
OBS! The webpage URL is this: (remove the space between "ht" and "tps") ht tps://w2.brreg.no/enhet/sok/detalj.jsp?orgnr=XXXXXXXXX
org.nr to test out is: 947054600
Hi @stein_fjellseth and welcome to the forum.
Try this:
{=extractregex({site: url}, "orgnr=(\d+)")}
Hei Stein! Velkommen 
The whole snippet will take some time to make, but I'll throw in a sample to give you a start.
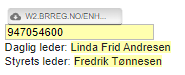
{urlload: https://w2.brreg.no/enhet/sok/detalj.jsp?orgnr={=orgnummer}; done=(contents)->["contents": contents]; method=GET}
{formtext: name=Orgnummer; default=947054600}
Daglig leder: {=extractdagligleder}
Styrets leder: {=extractstyretsleder}
{norskbokstav=replaceregex(contents, "ø", "ø", "g")}{extractstyretsleder=extractregex(norskbokstav, "<\b>Styrets leder:</b>
</p>
</div>
<div class=\"col-sm-8\">
<p style=\"height:12px\">(\D+)</p>")}{extractdagligleder=extractregex(contents, "<b>Daglig leder:</b>
</p>
</div>
<div class=\"col-sm-8\">
<p>(\D+)</p>")}
1 Like
Hei Benjamin! Takk for svar og TUSEN TAKK for hjelp! Men det jeg ikke klarer å forstå er hvordan jeg skal lage en snippet ut av dette som virker? Jeg tenkte å navngi snippetten /brreg, men når jeg klikker på "copy to textblaze" det du har laget, får jeg feilmeldingen: {urlload} URL must have a fixed domain like "https://example.com" Det er denne biten jeg ikke forstår... Vil være supertakknemlig om du hjelper meg i mål med dette Ønsker deg en super dag videre! Mvh Stein
Hei igjen Stein!
Det er bare hyggelig  Jeg ser nå at urlload-koden ble litt bugget grunnet formateringsregler her i forumet, men jeg har nå fikset opp i den (så gjerne forsøk å kopier over på nytt).
Jeg ser nå at urlload-koden ble litt bugget grunnet formateringsregler her i forumet, men jeg har nå fikset opp i den (så gjerne forsøk å kopier over på nytt).
Du må også huske å aktivere les/skriv fra brreg.no for snippetmappen (popper opp i bunnen av snippeten etter du har lagret den).
