Hello Community!
I am using the website tool to extract phone numbers from a website to send texts. I have a couple of things I am trying to figure out to make the snippets a little easier to read.
First, some profiles have multiple numbers so I am using the multiple option in the website feature. However, when the numbers are pulled, they are in this format, ["555-555-555", "555-555-5555"] which our phone application does not read. To fix this I am using this formula:
{phonenumber1=split({site: text; select=ifneeded; selector=#phone_number\ ; multiple=yes}, ",")[1]}{=extractregex(phonenumber1, "\w+-\w+-\w+")}
My problem is that 80% of the time, the phone number is formulated as 555-555-5555, but there are instances that it is formulated without the dashes. Is there another regex combination that will extract the numbers regardless of what format they are in?
Second issue: When running the snippet, some of the boxes will be empty and it will return a prompt like you see below:
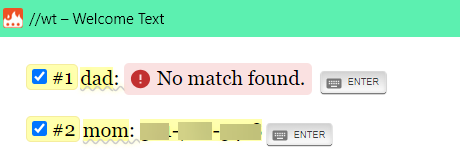

This just means that those boxes were left empty which is not an issue. The only ones I really want to focus on are when they are both empty like this:

Is there a way for me to tell the snippet:
-
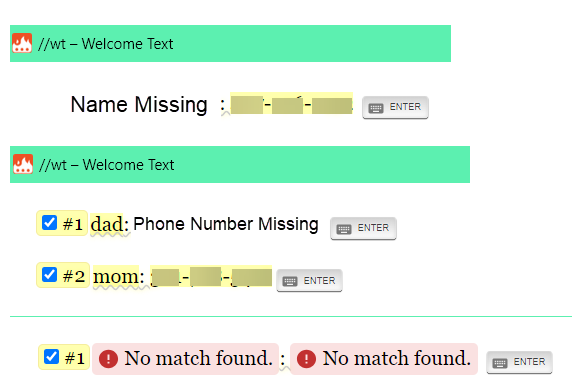
IF "Name1" is not found but "phonenumber1" is found", then return the text "Name Missing" instead of the "No Match Found" prompt.
-
IF "Name1" is found but "phonenumber1" is not found" then return the text "Phone number missing" instead of the "No Match Found" prompt.
-
IF "Name1" is not found AND "phonenumber1" is not found", then do nothing
It would look something like this:
Here is the snippet:
{note}{Name1=split({site: text; select=ifneeded; selector=[name="phone_description"]\ ; multiple=yes}, ",")[1]}{=extractregex(name1, "\w+")}: {endnote}{phonenumber1=split({site: text; select=ifneeded; selector=#phone_number\ ; multiple=yes}, ",")[1]}{=extractregex(phonenumber1, "\w+-\w+-\w+")}
Thank you!