Dear community, I have no clue how to extract information from a Gmail eMail to use it in Text Blaze. Since the eMail text position always change, I can't use the website text picker. Unfortunately, I also don't understand regex very well, but I think I could fix the problem with that!? or is it better to collect the data first to Data Blaze in a table and use it from there for Text Blaze? or do I need an eMail scrapper first to get out the data and import it as a CSV-File into Data Blaze?
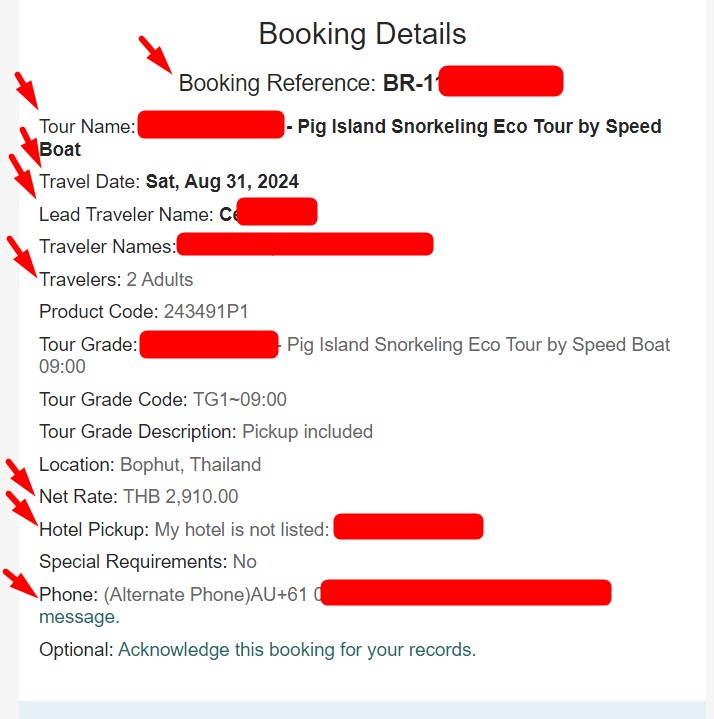
For my logic, I need something that check for the string, e.g. 'Lead Traveler Name:' and output the text after that string to Text Blaze.
I need the following information with an arrow from the Gmail eMail to use in Text Blaze:
What will be the best solution to create a snippet for that?
They can still be a bit tricky though. Our "AI Write" feature can help you build them.
For instance I asked AI Write to do this:
Use a regex to get the traveler name from the following text:
text...
text...
Lead Traveler Name: John Smith
text...
text...
And it returned a snippet with the correct formula for the regex.
Let me know if this helps! If you want further help extracting specific items from this email please include the text of the email (instead of a screenshot) in your response with any sensitive info redacted.
I got almost everything work, just the phone number and change the date format is the last problem
I can extract the line of phone number, but not only the phone number: {=extractregex({site: text; page=https://mail.google.com/*; select=ifneeded; selector=div > :nth-child(2) > tbody > tr > td > table > tbody > :nth-child(1)}, "Phone: (.*)")}
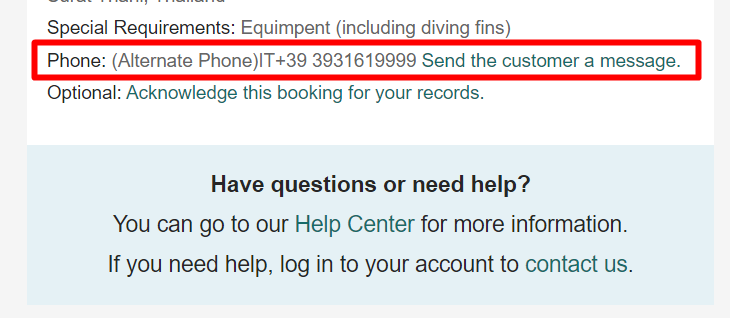
The Result will be: (Alternate Phone)IT+39 21221219999 Send the customer a message.
How can I extract only the numbers after the '+' (included the '+')
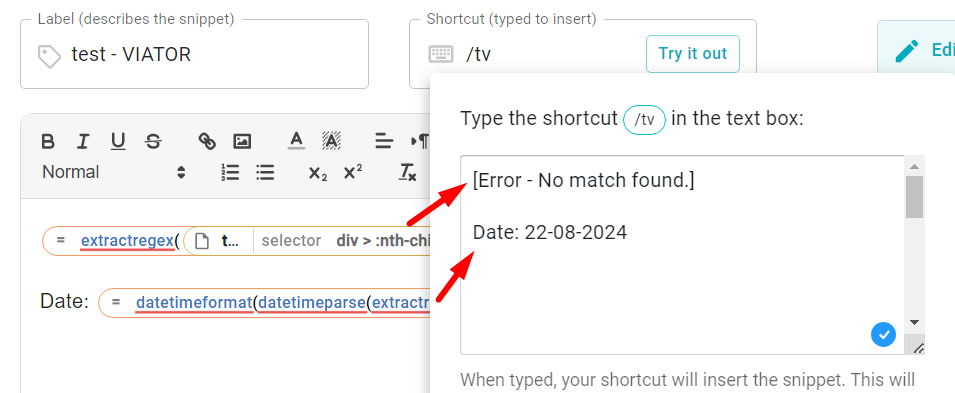
I can also extract the date and change the format, but I can't pull the correct date format into the place I need: Date: {=extractregex({site: text; page=https://mail.google.com/*; select=ifneeded; selector=div > :nth-child(2) > tbody > tr > td > table > tbody > :nth-child(1)}, "Travel Date: (.*)")}
The result will be: Date: Thu, Aug 22, 2024
Date: {=datetimeformat(datetimeparse("Thu, Aug 22, 2024", "ddd, MMM D, YYYY"), "DD-MM-YYYY")}
The result will be: Date: 22-08-2024 (this is the format I need)
How can I integrate the 'datetimeparse' into the exctractregex?
These might solve the date and phone issues for you:
Email text (you would get this from the page directly using the site command or maybe the clipboard command):
{formparagraph: default=
text...
text...
Lead Traveler Name: John Smith
(Alternate Phone)IT+39 21221219999 Send the customer a message.
Date: Thu, Aug 22, 2024
text...
; name=email; rows=8
}
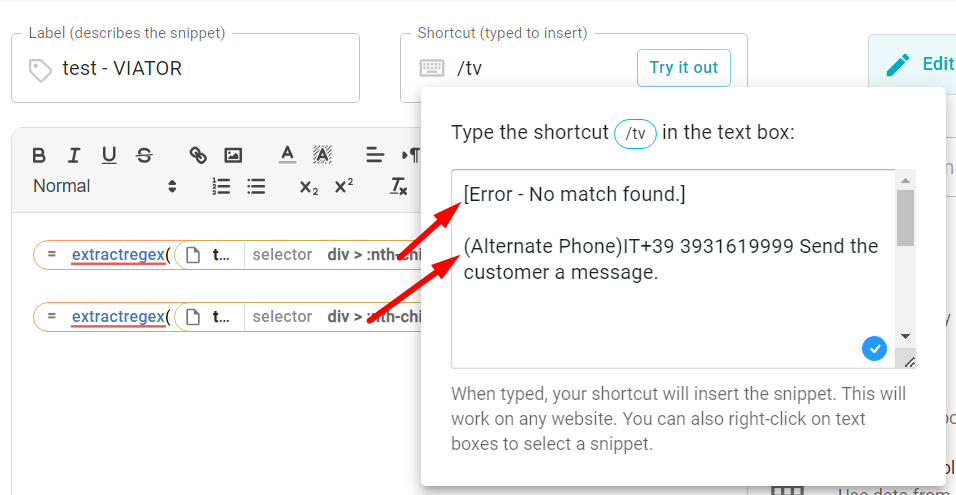
As you can see on the picture below there is an 'Error - No match found' with your formula: {=extractregex({site: text; page=https://mail.google.com/; select=ifneeded; selector=div > :nth-child(2) > tbody > tr > td > table > tbody > :nth-child(1)}, "Phone: ([+][0-9]) ")}
When I use the first formula, he will extract the whole line after 'Phone:' from the eMail: {=extractregex({site: text; page=https://mail.google.com/; select=ifneeded; selector=div > :nth-child(2) > tbody > tr > td > table > tbody > :nth-child(1)}, "Phone: (.)")}
but I just need the phone number, like this "+39 21221219999"
This is the original text from the eMail:
"Phone: (Alternate Phone)IT+39 21221219999 Send the customer a message."
I think it could be because there is no space before the '+' symbol?