This is a show and tell about a story that has only begun. It involves Text Blaze (of course) and a few other technologies that I've managed to delicately blend to produce some surprising results. This journey which led to the creation of an R&D project (named Quila) began when I read this document. However, Open AI and a variety of productivity challenges had been circling this project for many months.
What is Quila?
It all started when I was investigating better ways to reduce typing effort.Text Blaze, while a Chrome extension, stood out among the contenders lined up to take the baton from TextExpander. To be clear, I never had issues with TextExpander, I just had a new productivity requirement - the ability to perform modern API integrations as I composed content. Since most of my content development is in Coda, I searched for a programmable keyboard utility, and by “programmable”, I mean - is it capable of reading what I’m typing and use that content to generate additional content?
Why TextBlaze?
Text Blaze stole my heart despite its roots in Chrome. It supports all the usual text-expansion features as well as background integrations over HTTP which can be used with webhooks, APIs, and even web site scraping. Two key requirements concerning an open text-expander quickly emerges as I attempted to rethink text expansion in more productive ways.
- Integration with arbitrary systems
- Integration with the underlying canvas
Both are critical needs for my work with documents and while Coda itself provides integrations with Packs, there are some limitations; the canvas (for example) is inaccessible. Oddly, Text Blaze provides access to the content in the canvas using a formula {site: text}. This makes it possible for a keyboard extension to capture all text in the current page and without any highlighting, Cmd-C, or other steps - you just execute an expansion trigger. Here’s an example...
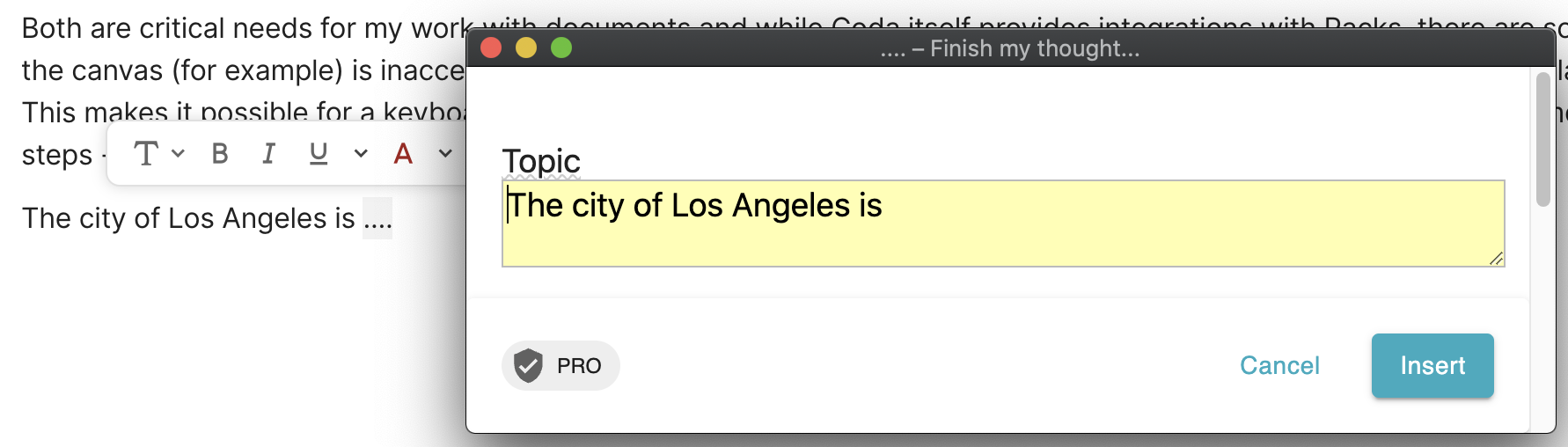
The city of Los Angeles is [....]
When I typed the fourth dot , Text Blaze captured the content in the Coda page and determined the line of text I was working with. It extracted this line, removed the four dots, and rendered it in a dialog box. The benefit of the dialog box is not obvious, but it will be.
The Brainstorm
What came next was a brainstorm. If it’s possible to instantly capture the current line and communicate with another system in that context, what other possibilities exist? I simply had to explore this capability more. I experimented for weeks with this basic feature. I created a number of prototypes that captured the line content in a Coda table and even found a way to automatically link the text line with an @reference to a table record. With some timely inspiration from this document, I wondered ...
What if the current line in a Coda document could be framed as a GP3 prompt?
I suspect that for most readers, the dialog box probably makes a little more sense as soon as you connect a few AI dots that lay on the horizon. Let’s continue to explore the incomplete line of text in the example and see what happens when we send that line off to GPT-3.
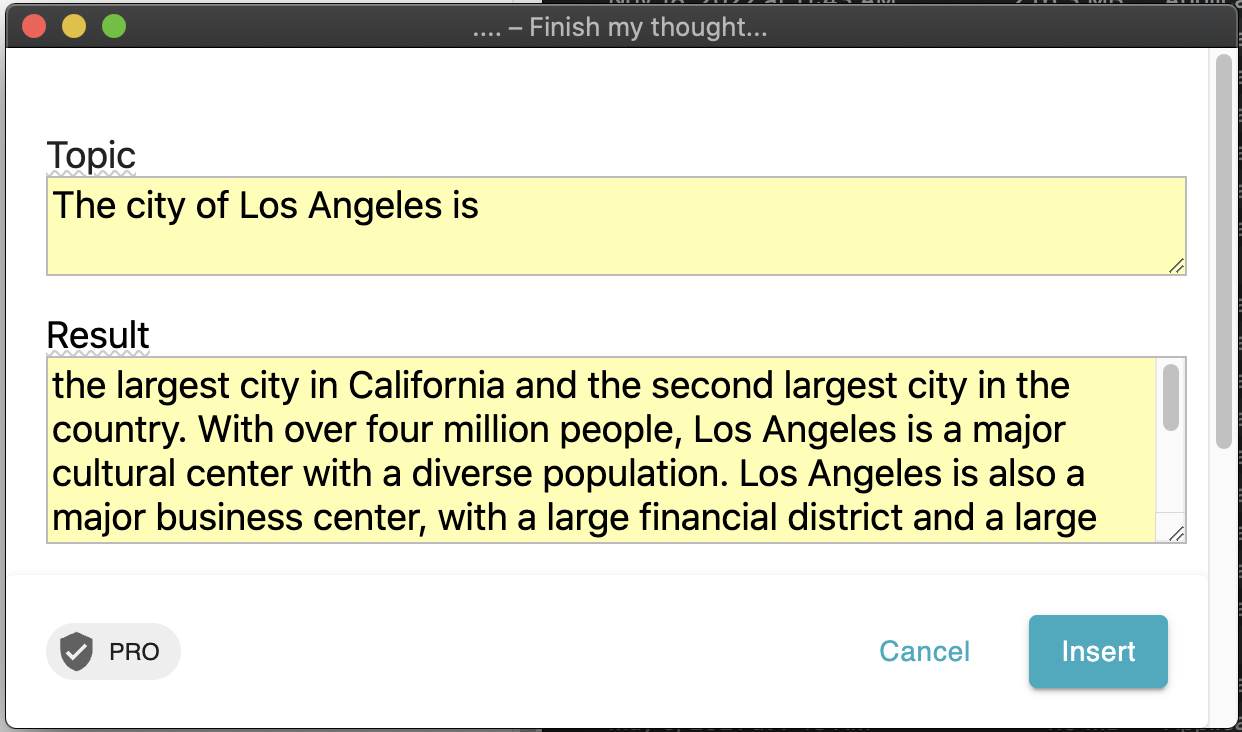
The city of Los Angeles is
We get a synopsis of Los Angeles. Clicking the [Insert] button drops in the content where the four dots were typed.
The city of Los Angeles is the largest city in California and the second largest city in the country. With over four million people, Los Angeles is a major cultural center with a diverse population. Los Angeles is also a major business center, with a large financial district and a large port. The city is home to many major corporations, media companies, and entertainment companies. Los Angeles is also a major tourist destination, with a large number of hotels, restaurants, and attractions.
I’m not easily impressed, but this was impressive. Still a lot of testing and research lay ahead. Is this approach repeatable? Yes, but not yet productized. Another simple test.
The area code for SLC is [....] Quila: SLC is in the 801 area code.
Pretty simple; possibly useful.
Full entity parsing and smart cursor insertion is on the horizon for the Quila project, but this demonstrates that by aligning a few simple off-the-shelf parts, I was able to create what may signal a future of hyper-productivity for my work. After all, we know that enterprise knowledge workers spend a fifth of their day groping for information to get work done. Is it possible that Text Blaze + Coda + GPT-3 could shave a few minutes from a counterproductive column and add it back to a productive column?
Saving One Minute = Two Minutes
For each minute that we can avoid hunting for information, it’s really worth two minutes of your day because of the nature of opportunity costs. VentureBeat: Report: Employees spend 3.6 hours each day searching for info, increasing burnout
There’s More
Yeah, with AI and the ability to conduct seamless work integration along with Coda’s modern idea of a “document”, my Quila research project is an ever-deepening world of possibilities.
What if we could force feed GP3 its own summarization results and ask it to produce just keywords?
Force the snake to eat its own tail? A second GPT-3 request quickly distills the keywords for the summary previously returned for Los Angeles. With the full dialog revealed, you can begin to see where this intersection of these products is leading.
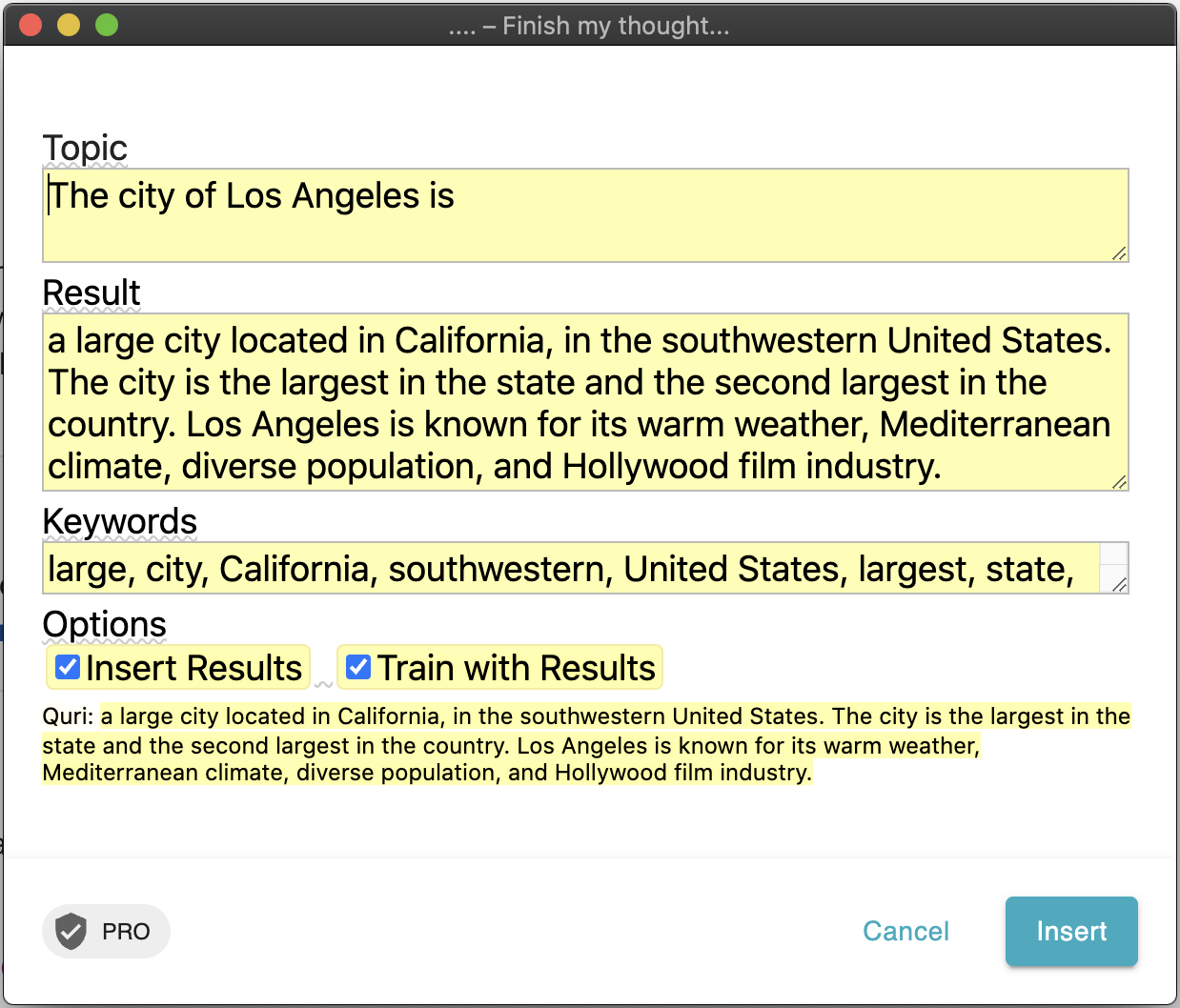
Let’s chat about the obvious - can this additional meta-data be captured in Coda for other uses? Indeed, and the uses will be numerous. The [....] expander not only makes two requests into GPT-3, but it also posts it’s results into a Coda table designed to track AI outcomes. This is not possible in any other text expander tool as far as I know.

Optionally, the Text Blaze dialog I crafted makes it possible to use or discard the results as well as capture as training assets. This reveals another key advantage to Text Blaze; automation logic is built in; it's a fairly comprehensive system of primitives that make almost any automation outcomes possible.
Seeing is Believing
By now you're probably thinking - I gotta' see this - so I created a brief video.
Machine Learning - the Pathway to Smart Documents
We often imagine how AI can help us without considering how we can help AI. In my work, I spend a lot of time designing and building in highway analytics testing and reporting systems using machine vision to count and classify vehicles as they race by in excess of 80 miles-per-hour. For each client, there are complex nuances, terminology, and technical rules. Over time, a Coda document emerges with deep content about the client, the environment where the solution operates, problems and challenges, and a number of rules and requirements that form the basis for a specific domain of expertise.
What if we could persist all GP3 results as an index of important data and content about a specific document? And then use it as a training set for specific deep work objectives?
Despite the real-time cataloging of GP3 results in a Coda table, we are unable to use that data directly at run-time when Text Blaze performs a keystroke operation. Reacting to keystrokes on the Coda canvas doesn’t give us any access to Coda content except the text in the page. Tables are off-limits as is the DOM. Accessing a JSON representation of any Coda data is also presently out of reach.
Coda Needs Events and Document Introspection
I’ve said this many times on Linkedin and the Coda forums - access to content and a model that supports webhook listeners for change events is desperately needed to build smarter document systems.
Certainly, mapping a Coda table into GP3 for additional training processes is wholly possible with Pack Studio. Quila currently uses GP3 model tuning customization to create a variant model with subtle awareness concerning the Coda document’s overarching domain of expertise. As more content is plowed into the document and elements are captured in the normal course of work, the model continues to get slightly better at predicting request outcomes within the more narrow boundaries of a document dedicated to specific deep work.
There’s little we can do to improve GP3 when asking a questions like these.

However, when specific answers and insights are needed that are domain-specific, GP3 needs a little help. In each of the questions concerning AUX lanes, there is only one AUX lane and four GP lanes at Cheyenne Boulevard.

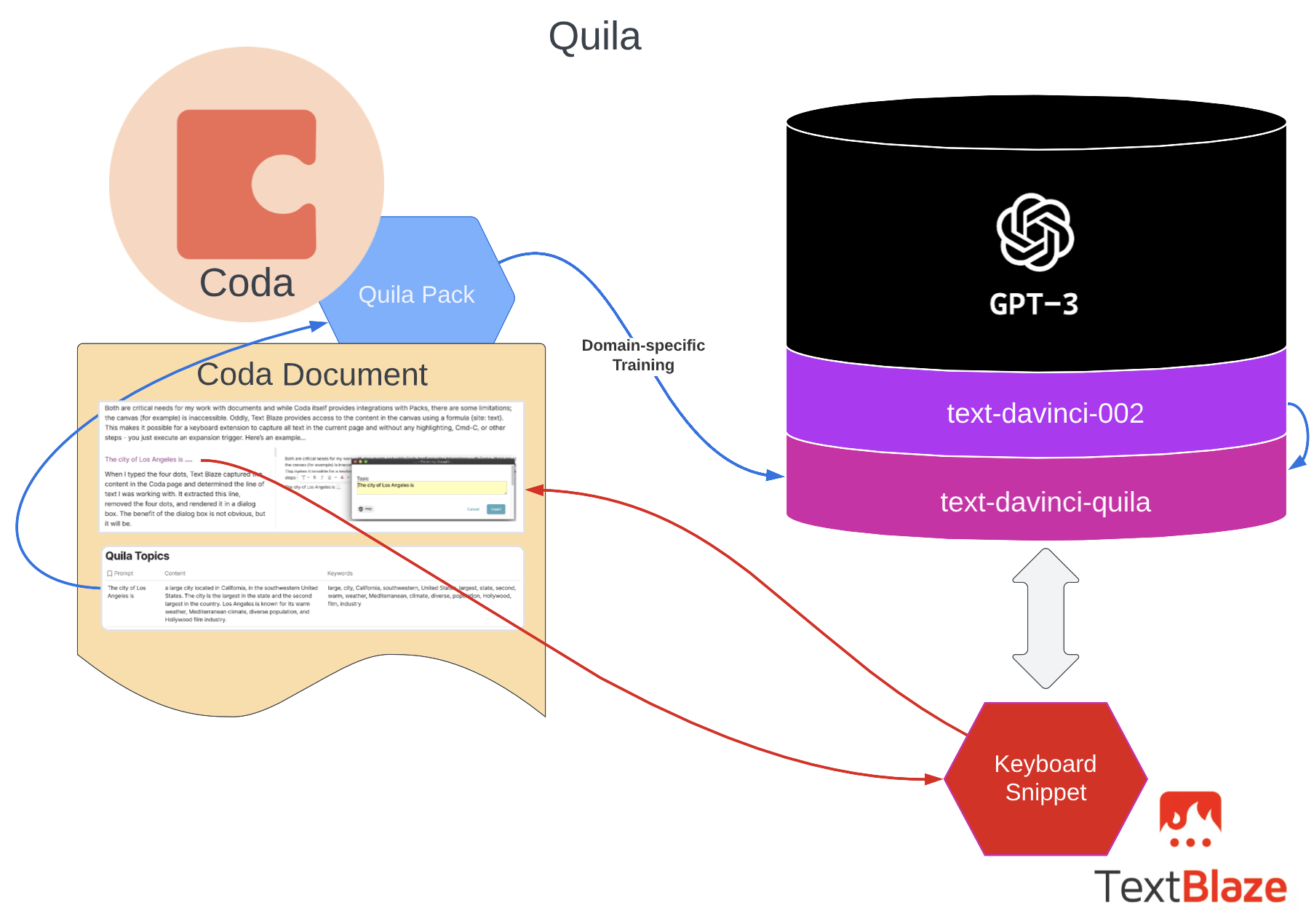
The Architecture
This provides a visual map of the general approach I’ve followed to create a few of the Quila features.
Circling Back - What is Quila?
It’s a research project intended to leverage new types of automation for rapid content development and hyper-productivity. The goal is simple - do more, know more, and in less time.
When will Quila be completed?
Never. Climbing and reaching higher to achieve greater productivity has no summit.
What’s with the name?
I like to label my work with a name I can easily remember (tequila without the “te”). I also pick names that can be typed rapidly; two keys on the left and three on the right. Of course, in Text Blaze it’s just “qq”. ![]() But, Quila (pronounced however you like) is "key-ah" to me, the term "key" being quite relevant.
But, Quila (pronounced however you like) is "key-ah" to me, the term "key" being quite relevant.
Sharing the Doc
There are a number of challenges to sharing a work like this because there is code and models that exists in three places:
- Coda Pack
- Text Blaze Snippets
- GP3 model
It will take some time to distill this into a clever and easily replicated solution, but wide open to a collaboration if anyone is interested. In the meantime, the video pretty much says all that can be shared at this time.
UPDATE: 2022-11-28 - here's the snippet source without API credentials in case you want to experiment.
{note: preview=yes}
Topic
{formparagraph: name=thisTopic; cols=48; rows=2}{thisTopic=thisLine}
Result
{formparagraph: name=aiContent; default=""; cols=48; rows=4}
Keywords
{formparagraph: name=aiKeywords; default=""; cols=48; rows=1}
Options
{formtoggle: name=Insert Results; default=yes}{endformtoggle} {formtoggle: name=Train with Results; default=yes}{endformtoggle}
{endnote}{if: `insert results` == "Yes"}{=replace(aiContent, "\n", ""); trim=yes}{endif}{note: preview=no}
{thisPage=split(split({site: text}, "Page options")[2], "Insert & explore features")[1]}
{=thisPage}{thisLine=""}
{repeat: for x in split({=thispage}, "\n"); trim=no}
{if: endswith(x, "....")}{thisLine=replace(x, "....", "")}{endif}
{endrepeat}
{if: thistopic <> ""}
{urlload: https://api.openai.com/v1/completions; method=POST; headers=Authorization:Bearer\ , Content-Type:application/json; body=\{ "model": "text-davinci-002", "prompt": "{=thisline}", "max_tokens": 512, "temperature": 1 \}; done=(res) -> ["res" : catch(fromJSON(res).choices, "???")]}
{aiContent=replace(res[1].text, "\n", "")}
{urlload: https://api.openai.com/v1/completions; method=POST; headers=Authorization:Bearer\ , Content-Type:application/json; body=\{ "model": "text-davinci-002", "prompt": "Extract keywords from this text:{=aicontent}", "max_tokens": 512, "temperature": 1 \}; done=(res) -> ["keywords" : catch(fromJSON(res).choices, "???")]}
{aiKeywords=replace(keywords[1].text, "\n", "")}
{if: `train with results` == "Yes"}
{urlsend: https://coda.io/apis/v1/docs/Bjn4yynsax/hooks/automation/grid-auto-E50xN-Ugri; method=POST; headers=Authorization:Bearer\ , Content-Type:application/json; body=\{
"items": [
\{
"Topic": "{=thistopic}",
"Content": "{=aicontent}",
"Keywords": "{=aikeywords}"
\}
]
\}}
{endif}
{endif}
{endnote}